AI could consume all online knowledge by 2026
Artificial intelligence (AI) systems, in their quest to achieve near-omniscience, could consume all freely available knowledge on the Internet by as early as 2026, according to a new study. AI models like GPT-4 and Claude 3 Opus depend on the vast troves of text shared online to enhance their capabilities.
However, projections indicate that the supply of publicly accessible data may be exhausted between 2026 and 2032. As a result, to advance AI models further, technology companies may need to turn to alternative data sources. These could include generating synthetic data, utilizing lower-quality sources, or, more concerningly, tapping into private data stored on servers, such as messages and emails.
“If chatbots consume all available data and there are no advances in data efficiency, I would expect to see relative stagnation in the field,” said Pablo Villalobos, lead author of a study recently published in the preprint server arXiv. “Models will only slowly improve over time as new algorithmic insights are discovered and new data is produced naturally.”
Training data fuels the advancement of AI systems, enabling them to recognize and incorporate increasingly complex patterns into their neural networks. For instance, ChatGPT was trained on around 570 GB of text data, comprising approximately 300 billion words sourced from books, online articles, Wikipedia, and other Internet resources.
Algorithms trained on insufficient or low-quality data yield unreliable outcomes. Google’s sentient Gemini AI, which controversially suggested adding glue to pizzas and eating rocks, derived some of its most questionable responses from posts on Reddit and articles on the satirical site The Onion.
To estimate the amount of text available online, the researchers utilized Google’s web index, determining that there are approximately 250 billion web pages, each containing an average of 7,000 bytes of text. They then analyzed Internet protocol (IP) traffic and online user activity to project the growth of this data pool.
Their findings indicate that high-quality information from trusted sources will be depleted by 2032 at the latest, while lower-quality linguistic data will be consumed between 2030 and 2050. As for image data, it is expected to be exhausted between 2030 and 2060.
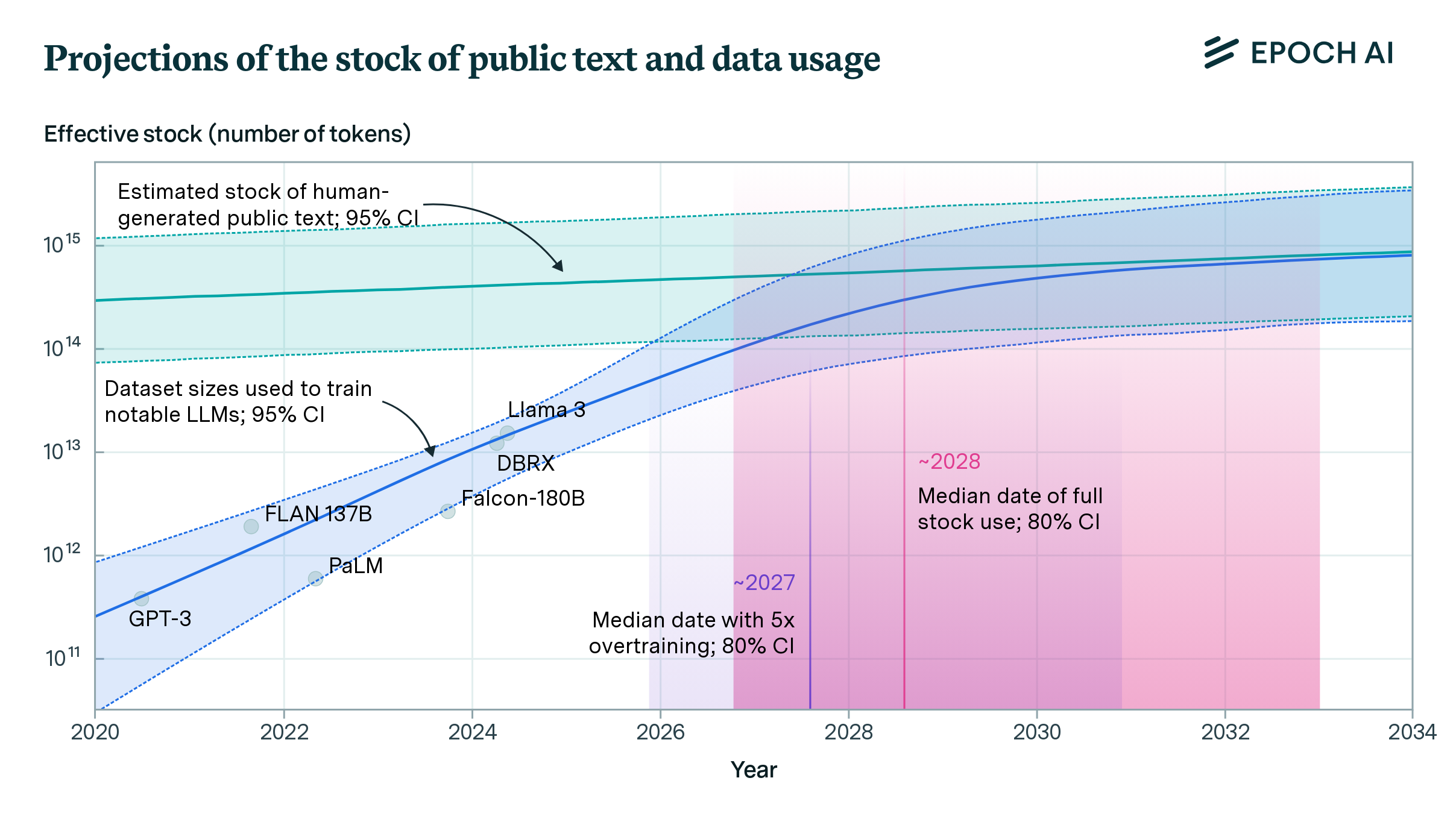
Neural networks demonstrate better predictive capabilities as their datasets grow, a phenomenon known as the law of neural scaling. Consequently, it remains uncertain whether companies can enhance their models’ efficiency to offset the lack of new data, or if this scarcity will lead to stagnation in model improvements. However, Villalobos suggests that data scarcity is unlikely to significantly impede the future growth of AI models. This is because companies have several potential strategies to circumvent the problem.
“Companies are increasingly trying to use private data to train models, such as Meta’s upcoming policy change,” he added, referring to the company’s announcement that it will use interactions with chatbots on its platforms to train its generative AI starting June 26. “If they are successful in doing so, and if the utility of private data is comparable to that of public web data, then it is quite likely that the major AI companies will have enough data to last until the end of the decade. At that point, other hurdles such as power consumption, rising training costs and hardware availability could become more pressing than lack of data.”
Another option is to use synthetic, artificially generated data to satisfy the demands of AI models, though this approach has so far been successful mainly in gaming, coding, and mathematics training systems. Alternatively, if companies attempt to gather intellectual property or private information without authorization, they could face legal challenges, according to some experts.
“Content creators have protested against the unauthorized use of their content to train AI models, with some suing companies such as Microsoft, OpenAI and Stability AI,” wrote Rita Matulionyte, a technology and intellectual property law expert and associate professor at Macquarie University, Australia, in The Conversation. “Being paid for their work can help restore some of the power imbalance that exists between creatives and AI companies.”
- See also: The world’s first bioprocessor
Researchers note that data scarcity is not the only obstacle to ongoing AI advancement. According to the International Energy Agency, ChatGPT-powered Google searches consume nearly ten times more electricity than traditional searches. This high energy demand has prompted tech leaders to invest in nuclear fusion startups to power their data centers, although this method of power generation is still far from being viable.